Быстрая свертка базы 1С через MSSQL.
Во встроенном языке 1С есть функция ПолучитьСтруктуруХраненияБазыДанных, которая дает нам дополнительные возможности по работе с базой данных 1С. Прямое обращение к таблицам позволяет в некоторых случаях значительно ускорить операции с БД.
Здесь предлагается обработка для свертки базы использующая прямое редактирование таблиц в MSSQL и позволяющая в разы сократить время сей операции.
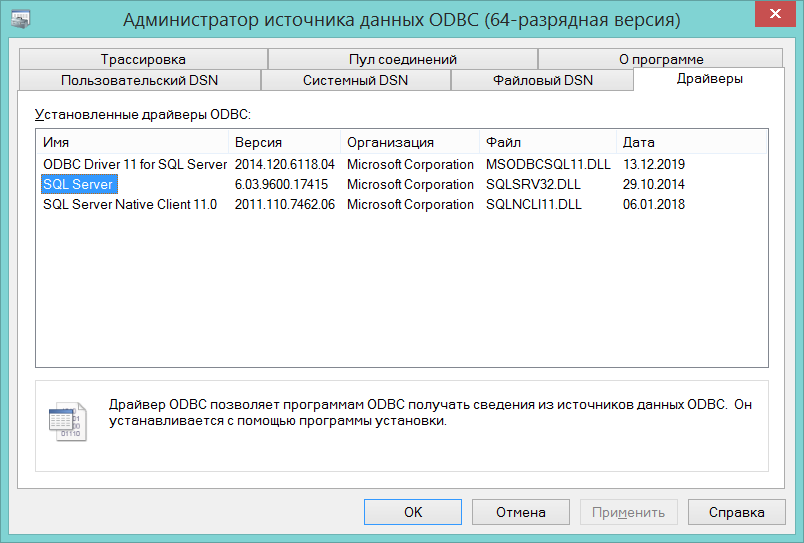
Обработка предназначена для использования программистами 1С. Настройки определены в модуле формы в процедуре ПриСозданииНаСервере. Из требований, это собственно сам MSSQL сервер, а также сервер и клиент 1С предприятия на виндус платформе. В виндузе, где запускается сервер 1С, должен быть установлен ODBC драйвер SQL Server с разрядностью соответствующей платформе 1С.
Как это работает.
В конфигурацию нужно добавить общий модуль СверткаБазы с галочкой Сервер, и скопировать туда полностью содержимое модуля объекта обработки. Модуль объекта обработки для вызовов здесь не используется, только для хранения текста для общего модуля, чтоб не плодить сущности. Обработку тоже можно добавить в конфигурацию, возможно так будет удобнее отлаживать, но это не обязательно. После всех процедур, их можно будет удалить.


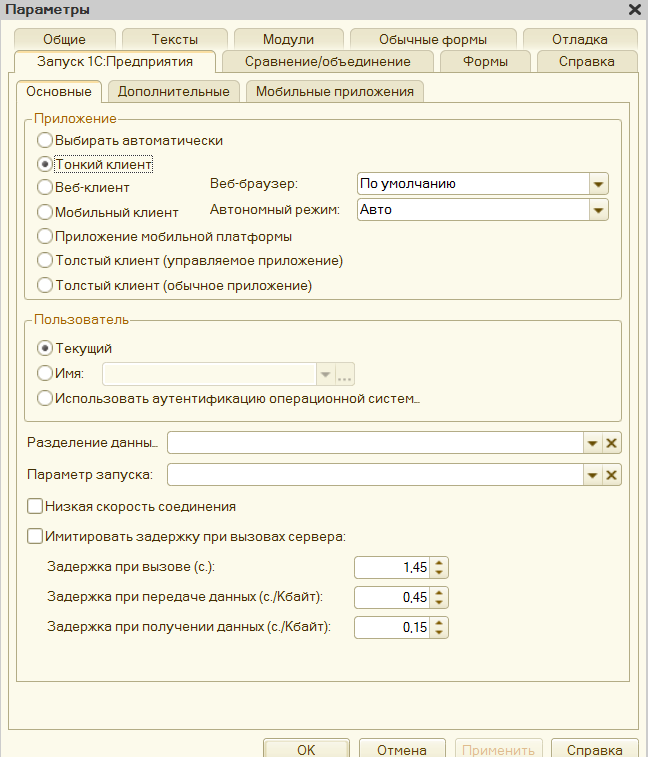
Форма обработки есть управляемая, поэтому, если вы используете обработку в толстой конфигурации, то включите использование управляемых форм в обычном приложении, или запускайте через тонкого клиента.
 или
или 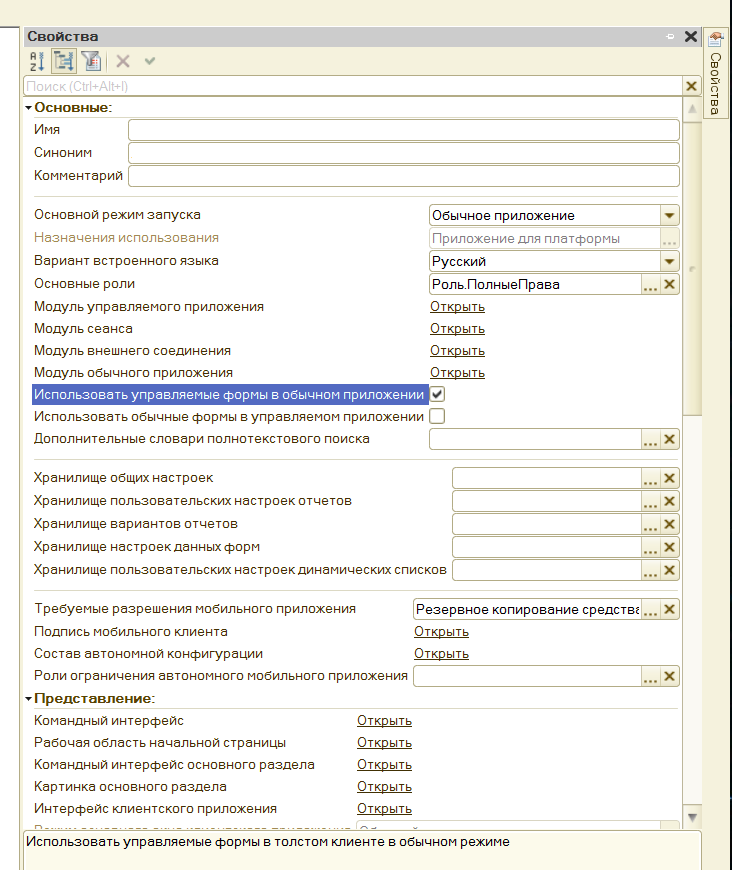
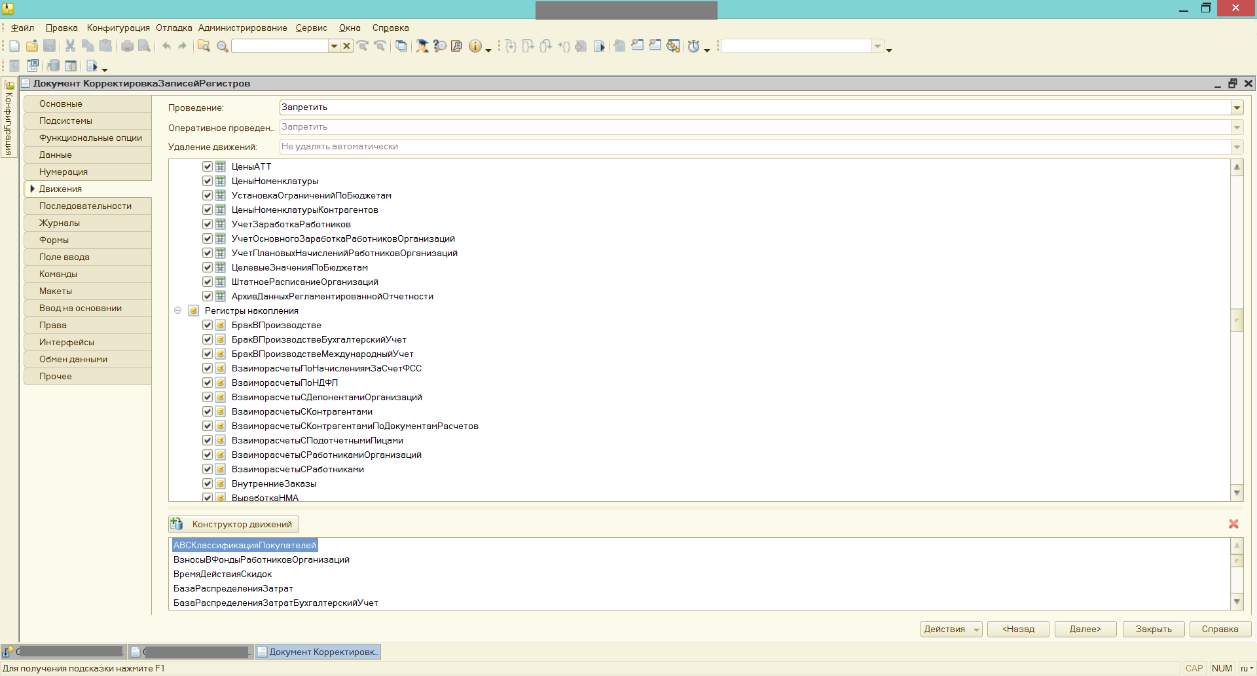
Отключите на время использование Регламентированных заданий во избежание, так сказать. Только не галочкой в консоли администрирования сервера, которая отключает все, т.к. мы будем использовать фоновые задания, они без нее тоже не работают. В конфигурации должен существовать документ КорректировкаЗаписейРегистров, в движениях которого должны быть выбраны регистры, по которым будут формироваться итоги на дату свертки. Это регистры накопления с остатками и зависимые от регистратора периодические регистры сведений. Обычно они и так выбраны в исходной конфигурации, но добавленные позже при доработках – нет. Если такого документа нет, то подгрузите его откуда-нибудь.
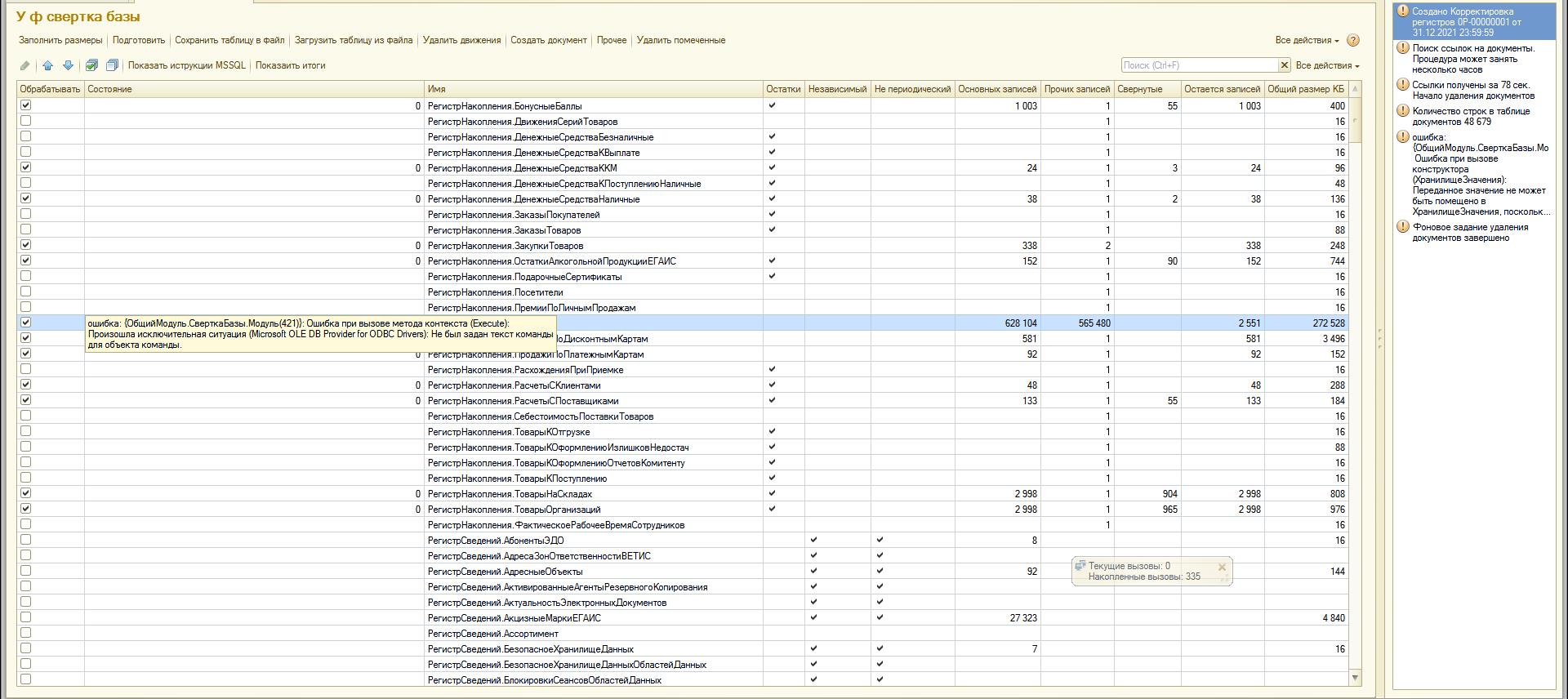
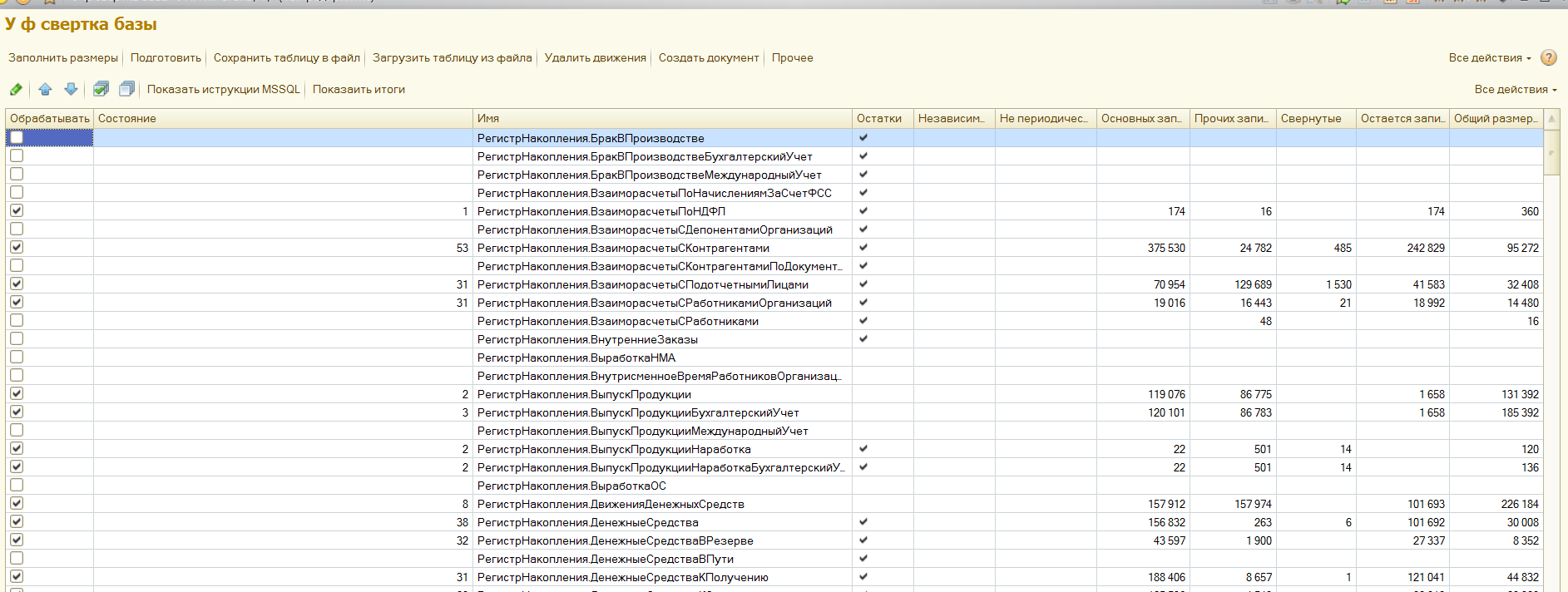
При запуске обработки открывается форма, в которую загружается список всех регистров. Используя кнопку ЗаполнитьРазмеры можно получить информацию о количестве записей и количестве отведенной памяти каждого регистра. При этом в колонке прочее суммируется информация по всем таблицам хранения кроме основной, это виртуальные, регистрации изменений и пр. На этом этапе уже задействуется механизм фоновых заданий. Для каждого регистра создается отдельное. В случае успеха в каждой соответствующей строке будет время выполнения в секундах.
По ходу экспериментов выяснилось, что платформа помнит только 1000 завершенных заданий. Ну действительно, я пытался разыскать в инете, что происходит с завершенными заданиями, как минимум их время жизни. Не нашел. И вопрос остался. С одной стороны, если задание завершено, то кто его знает через сколько времени я полезу посмотреть из основного потока чем там все закончилось. С другой стороны, сервер может работать много лет (смайлик) без перезапуска, нельзя все время только накапливать завершенные задания. Так что, если у вас больше 1000 регистров, то кто его знает, как все это будет работать, я не проверял.
Теперь, используя кнопку ПометитьВсе, нужно указать регистры для обработки. Автоматические пометки не ставятся на пустые регистры и на независимые-непериодические регистры сведений. Последние бывают больших размеров, и вы вручную можете указать какие-то для чистки. Содержимое будет удалено полностью. Можно регулировать и остальные пометки, но нужно точно понимать, что при этом происходит. Например, если вы снимаете пометку с какого-то регистра накопления, а движения по этому регистру делает документ, который будет помечен на удаление из-за другого регистра, с которого не снята пометка, то при Тестировании и Исправлении в конце свертки, движения первого таки будут удалены (должны, но я не проверял), а итогов на дату свертки по нему не будет. Такое можно было бы сделать, например, с регистром где нет движений ранее даты свертки, но это имеет мало смысла с точки зрения экономии времени.
Далее нужно запустить кнопку Подготовить. Здесь также запускаются отдельные задания для каждого регистра и это уже достаточно длительная операция. Основная идея в том, чтобы передать всю работу MSSQL серверу, он неплох в параллельных вычислениях, а конкурирующие запросы не конкурируют, т.к. идут к разным таблицам и не блокируют друг друга. Конечно здесь все упирается в скорость дисковой подсистемы. Но если база помещается, или почти помещается в отведенную для MSSQL оперативку, то все работает весьма шустро. На этом этапе подготавливаются инструкции SQL и вычисляются итоги на дату свертки. При этом используется параметр обработки КоличествоЗаписейУдаляемыхОдновременно предназначенный для ограничения роста журнала транзакций в дальнейших операциях. Инструкции DELETE будут формироваться с учетом этого параметра. Результаты работы можно посмотреть, выбрав строку и нажав ПоказатьИнструкцииMSSQL, или ПоказатьИтоги. Также заполняются колонки Свернутые и Остающиеся, соответственно для количества записей итогов на дату свертки и количества записей основной таблицы, которые позже даты свертки и останутся нетронутыми. Их сумма и будет количеством записей после окончания свертки в основной таблице (без учета виртуальных и пр.).
Чтобы не тратить время на подготовку в дальнейшем, можно сохранить состояние таблицы в файл. Имя файла должно быть предварительно задано в параметрах. Позже, если что-то пойдет не так, можно загрузить таблицу из файла вместо долгого вычисления итогов заново. И продолжить с этого места. Например, не так может пойти запись документа корректировки из-за границы запрета изменения данных.
Теперь кнопка УдалитьДвижения снова запускает набор фоновых заданий. Тоже длительная операция. Здесь уже нарушается согласованность таблиц базы. С этого момента и до окончания свертки Тестированием и Исправлением с пересчетом итогов, любые прочитанные данные другими клиентами или регламентными заданиями нужно считать неверными. На этом этапе MSSQL может выдавать ошибку для отдельных потоков о взаимной блокировке или прочие ошибки, как вариант, о таймауте соединения. Это не страшно, просто ошибочные потоки надо запустить на выполнение повторно после окончания остальных (сняв с завершившихся успешно пометки). Думаю, это происходит из-за попыток одновременно установить пометки удаления на разные документы в одних и тех же журналах. Как мне кажется проблема кроется в захвате участков индекса по которому отбираются записи для пометки удаления. Может быть можно будет организовать ожидание освобождения ресурса, или, как вариант, объединить обработку разных документов в одном журнале в одну инструкцию SQL. Возможно когда-нибудь я займусь этим, но в целом пока это не мешает. Вообще надо обращать внимание на содержимое поля Состояние, при нормальном завершении там всегда остается цифра, время выполнения потока, даже и ноль.
После окончания предыдущей процедуры нужно создать документ с итогами кнопкой СоздатьДокумент. Тоже занимает приличное время, так как создается один документ на все итоги. Можно было бы сделать отдельный документ на каждый регистр, но я не сделал. При записи документа могут возникнуть ошибки, когда запись из итогов не лезет в регистр. Одна из причин — это пустые значения в измерениях, которые не могут быть пустыми. Они могут возникать при Тестировании и Исправлении, когда удаляются ссылки на несуществующие объекты (сам не проверял). Такие записи придется обнаружить и исправить.
Наконец нужно запустить Тестирование и Исправление с пересчетом итогов. Если на копии базы ранее все свернулось чисто и логических ошибок не было, то на рабочей, для экономии времени, можно только пересчитать итоги.
Теперь база может быть доступна для работы пользователей. Помеченные на удаление документы могут удаляются одновременно с работающими пользователями. Большое их количество делает нежелательным, из-за продолжительности, использование стандартной процедуры удаления помеченных объектов. Но это уже на ваше усмотрение. Процедура удаления в обработке также проводит контроль наличия ссылок на документ перед его удалением. Это может занимать очень много времени, но так как не особо мешает работе пользователей, то вроде и нет проблемы. Функция НайтиПоСсылкам не зря в качестве аргумента принимает массив, т.к. процедура очень долгая и ее эффективность тем больше, чем больше объектов одновременно обрабатываются. Например, база на которой я готовил эту публикацию тратила 10 мин на поиск ссылок на 100 документов, 20 мин на поиск для 1000 документов, 40 мин на 10000, и 5 часов на все 350000 документов. Поэтому при удалении документов предпринимается попытка найти ссылки сразу на все помеченные. И хотя процедура выполняется в фоновом задании, отображение хоть какого-то прогресса во время поиска ссылок не имеет смысла. Клиент всего лишь контролирует активность задания. По окончании, результаты поиска сохраняются (имя файла должно быть задано в параметрах обработки) и начинается удаление. Периодически выводится информация об обработанных ссылках и сохраняется состояние. Таким образом можно прервать выполнение задания, если необходимо, а потом продолжить, не вызываю долгую процедуру поиска ссылок.
Лишним будет сказать, что перед сверткой рабочей базы, все действия необходимо произвести над копией базы, потом тщательно проверить результаты, и только после этого проводить процедуру на рабочей.
Если обработка окажется востребованной, то в планах будет добавить многопоточный пересчет итогов, возможно проверку целостности без монопольной блокировки базы, а также мелочи типа: размеры справочников, поиск ошибочных записей в итогах, выполнение последовательно без фона, проверка правильной конфигурации корректировки регистров, рекурсивная проверка циклических ссылок помеченных на удаление документов, [добавьте свое].
Свертка баз, быстро, дешево :-).
ЗЫ. Перед публикацией заметил прикольную ошибку в коде, которую решил не исправлять, т.к. она не влияет на задуманный алгоритм выполнения. А значит это не ошибка вовсе, а просто плохо читабельный код. Кстати, вот вам интересный вопрос.